Every time I think “Now I understand the Fourier Transform,” I am wrong.
Jean-Baptiste Joseph Fourier, 1768 – 1830. (Image source: Wikipedia)
Doing the Fourier Transform of a function is just seeing it from “another” point of view. The “usual” view of a function is in the standard basis . For example, can be seen as a vector (in the basis given by the elements in the domain) whose coordinates are the evaluations of on the elements in the domain. It can also be seen as a polynomial (in the monomial basis) whose coefficients are these evaluations. Let us call this vector .
The same function can also be seen from the “Fourier basis”, which is just another orthogonal basis, formed by the basis vectors . The th coordinate in the new basis will be given by inner product between and the th basis vector . We call these inner products the Fourier coefficients. The Discrete Fourier Transform matrix (the DFT matrix) “projects” a function from the standard basis to the Fourier basis in the usual sense of projection: taking the inner product along a given direction.
In this post, I am going to use elementary group theoretic notions, polynomials, matrices, and vectors. The ideas in this post will be similar to this Wikipedia article on Discrete Fourier Transform.
Please let me know in the comments if you find any error or confusion.
Roots of unity. Let be the the multiplicative group of th roots of unity. That is, . is a primitive th root if the smallest natural exponent that makes is . The root is principal if . In what follows, we assume that is a principal and primitive th root of unity.
Let be a field containing . For example, can be the set of complex numbers and where is the imaginary unit. It is easy to check that the roots appear on the unit circle of radius 1 around the origin.
Representing functions as polynomials and vectors. Let be the set of integers . To identify a function , it suffices to write down its evaluations on all . Thus we can treat as a -dimensional vector, whose th entry is just for . This shows that .
We can also represent the function (from the preceding paragraph) as a polynomial of degree at most , the representation being . This shows , where is the ring of polynomials with coefficients in and indeterminate , and the ring contains polynomials with degree at most . Why? Because when we take , we set every in , turning every into . Neat. (Why is a ring?)
The Chinese Remainder Theorem (CRT). The good news is, factors completely in because by assumption, contains all th roots of unity. This means, . Since the factors are relatively prime to each other, by the Chinese Remainder Theorem (CRT), there is a bijection which maps to a -tuple whose th entry is .
Essentially, the CRT says that “anything” expressed “with resptct to” can be equivalently expressed “with respect to” all individual factors , where
“anything” is a polynomial
expressing “with respect to” means computing .
From coefficients to evaluations. Given an , let us define the polynomials
and
for .
Note that by Euclid’s division algorithm, we can express
for some and where the degree of the remainder, , is strictly less than the degree of the divisor which means is just a scalar. It is easy to check that . The first equality is the definition of ; the second equality follows from the definition of and the Euclid expansion of ; the last equality follows from the Euclid expansion of if we substitute .
To reiterate,
.
This is magic.
Thus, the transformed polynomial can be completely described by the evaluations of over the roots of unity , the evaluations being .
Connections with polynomial interpolation. Notice that the above sentence sounds like an interpolation problem: every polynomial of degree at most can be reconstructed from evaluations in any field. Indeed, the Lagrange interpolation theorem is a restatement of the Chinese Remainder Theorem.
DFT: a change from the coefficient-basis to the evaluation-basis. The transform is the Discrete Fourier Transform. The th coefficient of the transformed polynomial is called the th Fourier coefficient of . A root of unity , when treated as a function defined as for any , is called a character of . We can also represent in the vector form as
.
The Fourier Transform maps a function from the standard basis (i.e., the monomial basis or the coefficient basis) to the Fourier basis (i.e., the evaluation basis) given by the characters . Recall that in polynomial representation, . Similarly, we can write the function as the -dimensional vector where
where is the usual inner product.
The matrix of the transform. So, how does the transform look like? Let , where both are tread as dimensional vectors over , where the th coordinate of is . We can readily see that makes sense as a matrix-vector multiplication, when the th row of the matrix is the transpose of the vector . All told, the matrix , containing at its row and column , is the Discrete Fourier Transform matrix. The above construction works even when is not a prime. (Notice that we have abused the notation and used to denote both a linear transform and its matrix.)
Actually, I think I missed a scale-factor. The coefficients of the Discrete Fourier Transform of a function are actually scaled by a factor . I will correct my derivation later. The above discussion at least gives the structural insight behind the Fourier Transform.
Afterthoughts. The transform is discrete because of the multiplicative group of the roots of unity, , is a finite group. It is isomorphic to under a map which sends the generator of (which is when is a prime) to the generator of , which is . The transform is also linear, because the inner product formulation is linear in both the coefficients of and entries of the matrix .
A glimpse of the uncertainty principle. The weight of a polynomial is the number of its nonzero coefficients. Loosely speaking, the uncertainty principle says that the weight of and cannot both be sparse. An extreme example is that if has only one nonzero coefficient, none of its Fourier coefficients is zero. Similarly, if has no nonzero coefficient, then its Fourier transform has weight one. Let’s examine below why that is true.
A (Dirac) delta function can be represented as a vector with all zero entries except at coordinate , which contains . A uniform function for all will be the vector , where is the all-ones vector.
Everyone tells us that the Fourier transform of is , and the Fourier transform of is . If we see the Fourier Transform as multiplying a vector by the matrix , it is easy to see why.
All entries in the first row and column of the matrix are , becasue their values are where either or is zero. Multiplying with gives us the th column of , which is when . Otherwise, all Fourier coefficients of are nonzero. In particular, .
In contrast, multiplying with the vector adds up all columns of (times the scale factor ). This makes each Fourier coefficient (except the th coefficient) equal to the sum of all roots of unity, and this sum is zero. To see this, note that where . Since satisfies , this implies . Since , it follows that , which is the sum of all th root of unity, must be zero. On the other hand, the th coefficient is just the sum of ones. Hence, .




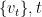







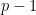





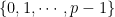


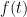

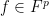
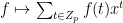
![f \in R=F[x] / (x^p - 1)](https://s0.wp.com/latex.php?latex=f+%5Cin+R%3DF%5Bx%5D+%2F+%28x%5Ep+-+1%29&bg=ffffff&fg=000000&s=0&c=20201002)
![F[x]](https://s0.wp.com/latex.php?latex=F%5Bx%5D&bg=ffffff&fg=000000&s=0&c=20201002)














means computing
.
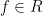
![f \in F[x]](https://s0.wp.com/latex.php?latex=f+%5Cin+F%5Bx%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![g \in F[x]\,, g(x) \triangleq f(x) \bmod (x - \omega_p^t)\,,](https://s0.wp.com/latex.php?latex=g+%5Cin+F%5Bx%5D%5C%2C%2C+g%28x%29+%5Ctriangleq+f%28x%29+%5Cbmod+%28x+-+%5Comega_p%5Et%29%5C%2C%2C&bg=ffffff&fg=000000&s=0&c=20201002)
![\hat{f} \in F[x] : F \rightarrow F\,, \hat{f}(t) \triangleq g(\omega_p^t)](https://s0.wp.com/latex.php?latex=%5Chat%7Bf%7D+%5Cin+F%5Bx%5D+%3A+F+%5Crightarrow+F%5C%2C%2C+%5Chat%7Bf%7D%28t%29+%5Ctriangleq+g%28%5Comega_p%5Et%29&bg=ffffff&fg=000000&s=0&c=20201002)
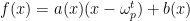

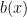
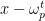














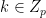



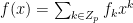



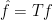





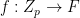
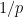

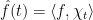

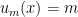



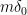
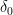
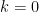



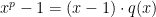



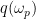


One thought on “Discrete Fourier Transform: the Intuition”