In a blockchain protocol such as Bitcoin, the users see the world as a sequence of states. A simple yet functional view of this world, for the purpose of analysis, is a Boolean string  of zeros and ones, where each bit is independently biased towards
of zeros and ones, where each bit is independently biased towards  favoring the “bad guys.”
favoring the “bad guys.”
A bad guy is activated when  for some
for some  . He may try to present the good guys with a conflicting view of the world, such as presenting multiple candidate blockchains of equal length. This view is called a “fork”. A string
. He may try to present the good guys with a conflicting view of the world, such as presenting multiple candidate blockchains of equal length. This view is called a “fork”. A string 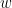 that allows the bad guy to fork (with nonnegligible probability) is called a “forkable string”. Naturally, we would like to show that forkable strings are rare: that the manipulative power of the bad guys over the good guys is negligible.
that allows the bad guy to fork (with nonnegligible probability) is called a “forkable string”. Naturally, we would like to show that forkable strings are rare: that the manipulative power of the bad guys over the good guys is negligible.
Claim ([1], Bound 2). Suppose  is a Boolean string, with every bit independently set to with probability
is a Boolean string, with every bit independently set to with probability 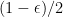 for some
for some  . The probability that is forkable is at most
. The probability that is forkable is at most  .
.
In this post, we present a commentary on the proof that forkable strings are rare. I like the proof because it uses simple facts about random walks, generating functions, and stochastic domination to bound an apparently difficult random process.
Continue reading “Forkable Strings are Rare” →
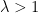



 random bits and he is allowed to look into the proof
random bits and he is allowed to look into the proof  in
in 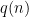 many locations. If the string
many locations. If the string  is indeed in the language, then there exists a proof so that the verifier always accepts. However, if
is indeed in the language, then there exists a proof so that the verifier always accepts. However, if  is not in the language, no prover can convince this verier with probability more than
is not in the language, no prover can convince this verier with probability more than  . The proof has to be short i.e., of size at most
. The proof has to be short i.e., of size at most  . This class of language is designated as PCP[r(n), q(n)].
. This class of language is designated as PCP[r(n), q(n)].![NP = PCP[O(\log n), O(1)]](https://s0.wp.com/latex.php?latex=NP+%3D+PCP%5BO%28%5Clog+n%29%2C+O%281%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) .
.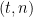 -Secret Sharing Scheme
-Secret Sharing Scheme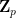 and selects a random polynomial
and selects a random polynomial 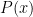 of degree at most
of degree at most 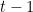 over this group. He sets the constant coefficient equal to your secret
over this group. He sets the constant coefficient equal to your secret  , then distributes
, then distributes  arbitrary evaluations of this polynomial as shares to the
arbitrary evaluations of this polynomial as shares to the  of the group
of the group  along with
along with  for each coefficient of the polynomial
for each coefficient of the polynomial  .
. are still private. What if we want everyone to be able to verify the correctness of all shares without knowing what the shares are? This is achieved by a Publicly Verifiable Secret Sharing Scheme, such as the one developed by
are still private. What if we want everyone to be able to verify the correctness of all shares without knowing what the shares are? This is achieved by a Publicly Verifiable Secret Sharing Scheme, such as the one developed by  , the encoding/decoding process uses only Boolean addition/rotation operation and no finite field operation. These codes are also MDS (Maximum Distance Separable), which means they have the largest possible (minimum) distance for a fixed message-length and codeword-length.
, the encoding/decoding process uses only Boolean addition/rotation operation and no finite field operation. These codes are also MDS (Maximum Distance Separable), which means they have the largest possible (minimum) distance for a fixed message-length and codeword-length. data components and
data components and  parity components in its generator matrix in standard form, its distance is at most
parity components in its generator matrix in standard form, its distance is at most 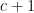 by the Singleton bound. Hence the code is MDS if and only if it can tolerate
by the Singleton bound. Hence the code is MDS if and only if it can tolerate  instead of
instead of 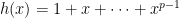 as in the case of BBV code
as in the case of BBV code is “large enough” and has a
is “large enough” and has a 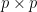 Discrete Fourier Transform matrix over the field
Discrete Fourier Transform matrix over the field  are nonsingular?
are nonsingular? has a singular submatrix.
has a singular submatrix.
 . For example,
. For example,  can be seen as a vector (in the basis given by the elements in the domain) whose coordinates are the evaluations of
can be seen as a vector (in the basis given by the elements in the domain) whose coordinates are the evaluations of  .
.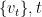 . The
. The  . We call these inner products the Fourier coefficients. The Discrete Fourier Transform matrix (the DFT matrix) “projects” a function from the standard basis to the Fourier basis in the usual sense of projection: taking the inner product along a given direction.
. We call these inner products the Fourier coefficients. The Discrete Fourier Transform matrix (the DFT matrix) “projects” a function from the standard basis to the Fourier basis in the usual sense of projection: taking the inner product along a given direction. . Let
. Let ![F_2[x]](https://s0.wp.com/latex.php?latex=F_2%5Bx%5D&bg=ffffff&fg=000000&s=0&c=20201002) be the ring the polynomials with indeterminate
be the ring the polynomials with indeterminate 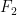 . The polynomial
. The polynomial ![(x^p-1) \in F_2[x]](https://s0.wp.com/latex.php?latex=%28x%5Ep-1%29+%5Cin+F_2%5Bx%5D&bg=ffffff&fg=000000&s=0&c=20201002) factors over
factors over 





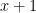 the trivial factor since the root
the trivial factor since the root  already belongs to
already belongs to 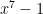 , each of degree 3, whereas
, each of degree 3, whereas  has only one non-trivial irreducible factor of degree 12? It appears that either there is only one nontrivial factor, or the degree of all nontrivial factors is the same. Why?
has only one non-trivial irreducible factor of degree 12? It appears that either there is only one nontrivial factor, or the degree of all nontrivial factors is the same. Why?![f(X)=X^p-1 \in F_l[X]](https://s0.wp.com/latex.php?latex=f%28X%29%3DX%5Ep-1+%5Cin+F_l%5BX%5D&bg=ffffff&fg=000000&s=0&c=20201002) for a prime
for a prime ![R=F_l[X]/(f)](https://s0.wp.com/latex.php?latex=R%3DF_l%5BX%5D%2F%28f%29&bg=ffffff&fg=000000&s=0&c=20201002) . Via the Chinese Remainder Theorem, this question is equivalent to finding a factorization of
. Via the Chinese Remainder Theorem, this question is equivalent to finding a factorization of  . Suppose
. Suppose 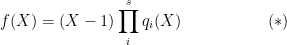
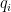 is an irreducible polynomial. What are the degrees of
is an irreducible polynomial. What are the degrees of 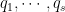 ? What is
? What is  ?
?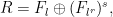 where
where  is the multiplicative order of
is the multiplicative order of 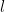 mod
mod  above. We’ll talk about these connections in another post. The content of this post is Proposition 2.6(3) from their paper.
above. We’ll talk about these connections in another post. The content of this post is Proposition 2.6(3) from their paper.