In a blockchain protocol such as Bitcoin, the users see the world as a sequence of states. A simple yet functional view of this world, for the purpose of analysis, is a Boolean string  of zeros and ones, where each bit is independently biased towards
of zeros and ones, where each bit is independently biased towards  favoring the “bad guys.”
favoring the “bad guys.”
A bad guy is activated when  for some
for some  . He may try to present the good guys with a conflicting view of the world, such as presenting multiple candidate blockchains of equal length. This view is called a “fork”. A string
. He may try to present the good guys with a conflicting view of the world, such as presenting multiple candidate blockchains of equal length. This view is called a “fork”. A string 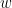 that allows the bad guy to fork (with nonnegligible probability) is called a “forkable string”. Naturally, we would like to show that forkable strings are rare: that the manipulative power of the bad guys over the good guys is negligible.
that allows the bad guy to fork (with nonnegligible probability) is called a “forkable string”. Naturally, we would like to show that forkable strings are rare: that the manipulative power of the bad guys over the good guys is negligible.
Claim ([1], Bound 2). Suppose  is a Boolean string, with every bit independently set to with probability
is a Boolean string, with every bit independently set to with probability 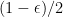 for some
for some  . The probability that is forkable is at most
. The probability that is forkable is at most  .
.
In this post, we present a commentary on the proof that forkable strings are rare. I like the proof because it uses simple facts about random walks, generating functions, and stochastic domination to bound an apparently difficult random process.
Continue reading “Forkable Strings are Rare” →
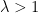





 . At every time-step (or “epoch”)
. At every time-step (or “epoch”)  it takes a
it takes a 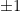 vertical step. At every step, the particle either moves up by
vertical step. At every step, the particle either moves up by 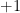 , or down by
, or down by 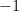 . This walk is “unbiased” in the sense that the up/down steps are equiprobable.
. This walk is “unbiased” in the sense that the up/down steps are equiprobable. for the first time? Contents of this post are a summary of the Chapter “Random Walks” from the awesome “Introduction to Probability” (Volume I) by William Feller. Also,
for the first time? Contents of this post are a summary of the Chapter “Random Walks” from the awesome “Introduction to Probability” (Volume I) by William Feller. Also, ![\displaystyle p:=\Pr[ \text{down}]\, ,\qquad q:=\Pr[ \text{up} ]\, ,\qquad p + q = 1](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+p%3A%3D%5CPr%5B+%5Ctext%7Bdown%7D%5D%5C%2C+%2C%5Cqquad+q%3A%3D%5CPr%5B+%5Ctext%7Bup%7D+%5D%5C%2C+%2C%5Cqquad+p+%2B+q+%3D+1&bg=ffffff&fg=000000&s=0&c=20201002) .
.![\displaystyle p:=\Pr[ \text{down}]\, ,\qquad q:=\Pr[ \text{up} ]\, , \qquad \Pr[stay] = r\, ,\qquad p + q = 1](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+p%3A%3D%5CPr%5B+%5Ctext%7Bdown%7D%5D%5C%2C+%2C%5Cqquad+q%3A%3D%5CPr%5B+%5Ctext%7Bup%7D+%5D%5C%2C+%2C+%5Cqquad+%5CPr%5Bstay%5D+%3D+r%5C%2C+%2C%5Cqquad+p+%2B+q+%3D+1&bg=ffffff&fg=000000&s=0&c=20201002) .
. .
.
 at time
at time  . At every time step, it independently takes a step up or down: up with probability
. At every time step, it independently takes a step up or down: up with probability  and down with probability
and down with probability  . If
. If  the walk is called symmetric. Let
the walk is called symmetric. Let  . If the walk reaches either
. If the walk reaches either ![\displaystyle p_z := \Pr[ \text{walk reaches } a \text{ before hitting }0]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+p_z+%3A%3D+%5CPr%5B+%5Ctext%7Bwalk+reaches+%7D+a+%5Ctext%7B+before+hitting+%7D0%5D&bg=ffffff&fg=000000&s=0&c=20201002) .
.![\displaystyle q_z := \Pr[ \text{walk hits zero before hitting }a]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+q_z+%3A%3D+%5CPr%5B+%5Ctext%7Bwalk+hits+zero+before+hitting+%7Da%5D&bg=ffffff&fg=000000&s=0&c=20201002) .
. .
.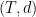 be a finite metric space. Let
be a finite metric space. Let  be a Gaussian process where each
be a Gaussian process where each 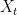 is a zero-mean Gaussian random variable. The distance between two points
is a zero-mean Gaussian random variable. The distance between two points  is the square-root of the covariance between
is the square-root of the covariance between 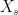 and
and 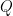 .
. be?
be?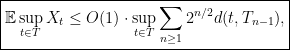
 is the distance between the point
is the distance between the point  , and
, and  is a specific sequence of sets with
is a specific sequence of sets with  . Constructions of these sets will be discussed in a subsequent post.
. Constructions of these sets will be discussed in a subsequent post. and any number
and any number  ? If we know the mean of
? If we know the mean of  , and
, and 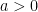 is a positive number, then
is a positive number, then![Pr[|X| \geq a] \leq \frac{|\mu|}{a}](https://s0.wp.com/latex.php?latex=Pr%5B%7CX%7C+%5Cgeq+a%5D+%5Cleq+%5Cfrac%7B%7C%5Cmu%7C%7D%7Ba%7D&bg=ffffff&fg=000000&s=0&c=20201002)

{kind=link}