Let . Let with distinc s. Let be a set of distinct nonnegative row-powers. Consider the Generalized Vandermonde matrix. When , this matrix becomes the ordinary Vandermonde matrix, .
An equivalent description of is the largest row-power and the set of missing rows from : that is, the items that are in but not in . Let be this set. Define the punctured Generalized Vandermonde matrix . Let be the th elementary symmetric polynomial.
Now we are ready to present some interesting results without proof, from the paper “Lower bound on Sequence Complexity” by Kolokotronis, Limniotis, and Kalouptsidis.
This is an elementary (yet important) fact in matrix analysis.
Statement
Let be an complex Hermitian matrix which means where denotes the conjugate transpose operation. Let be two different eigenvalues of . Let be the two eigenvectors of corresponding to the two eigenvalues and , respectively.
Then the following is true:
Here denotes the usual inner product of two vectors .
We will show that the eigenvalues of the Laplacian matrix of the complete graph are where the eigenvalue has (algebraic) multiplicity and the eigenvalue has multiplicity .
Rectilinear minimum spanning tree (source: Rocchini)
In this post, we provide a proof of Kirchhoff’s Matrix Tree theorem [1] which is quite beautiful in our biased opinion. This is a 160-year-old theorem which connects several fundamental concepts of matrix analysis and graph theory (e.g., eigenvalues, determinants, cofactor/minor, Laplacian matrix, incidence matrix, connectedness, graphs, and trees etc.). There are already many expository articles/proof sketches/proofs of this theorem (for example, see [4-6, 8,9]). Here we compile yet-another-expository-article and present arguments in a way which should be accessible to the beginners.
Statement
Suppose is the Laplacian of a connected simple graph with vertices. Then the number of spanning trees in , denoted by , is the following:
The reader is a beginner, like me, and have already glanced through the Spielman-Srivastava paper (from now on, the SS paper).
The reader has, like me, a basic understanding of spectral sparsification and associated concepts of matrix analysis. I will assume that she has read and understood the Section 2 (Preliminaries) of the SS paper.
The reader holds a copy of the SS paper while reading my post.
First, I will mention the main theorems (actually, I will mention only what they “roughly” say).
![[n] := \{0, 1, 2, \cdots, n -1 \}](https://s0.wp.com/latex.php?latex=%5Bn%5D+%3A%3D+%5C%7B0%2C+1%2C+2%2C+%5Ccdots%2C+n+-1+%5C%7D&bg=ffffff&fg=000000&s=0&c=20201002)

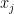
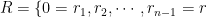
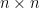
![V(x ; R) := \left( x_j^{r_i} \right)_{i,j \in [n]}](https://s0.wp.com/latex.php?latex=V%28x+%3B+R%29+%3A%3D+%5Cleft%28+x_j%5E%7Br_i%7D+%5Cright%29_%7Bi%2Cj+%5Cin+%5Bn%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![R = [n]](https://s0.wp.com/latex.php?latex=R+%3D+%5Bn%5D&bg=ffffff&fg=000000&s=0&c=20201002)
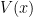

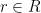
![[r]](https://s0.wp.com/latex.php?latex=%5Br%5D&bg=ffffff&fg=000000&s=0&c=20201002)

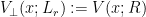
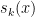

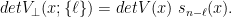
![det V_{\perp}(x ; \{\ell_0, \ell_1\}) = det V(x) \ det \left( s_{n-\ell_i+j}(x) \right)_{i,j \in [2]}.](https://s0.wp.com/latex.php?latex=det+V_%7B%5Cperp%7D%28x+%3B+%5C%7B%5Cell_0%2C+%5Cell_1%5C%7D%29+%3D+det+V%28x%29+%5C+det+%5Cleft%28+s_%7Bn-%5Cell_i%2Bj%7D%28x%29+%5Cright%29_%7Bi%2Cj+%5Cin+%5B2%5D%7D.&bg=ffffff&fg=000000&s=0&c=20201002)
![det V_{\perp}(x ; L) = det V(x) \ det \left( s_{n-\ell_i+j}(x) \right)_{i,j \in [s]} \text{ where } L = \{ \ell_0, \ell_1, \cdots, \ell_{s-1}\}.](https://s0.wp.com/latex.php?latex=det+V_%7B%5Cperp%7D%28x+%3B+L%29+%3D+det+V%28x%29+%5C+det+%5Cleft%28+s_%7Bn-%5Cell_i%2Bj%7D%28x%29+%5Cright%29_%7Bi%2Cj+%5Cin+%5Bs%5D%7D+%5Ctext%7B+where+%7D+L+%3D+%5C%7B+%5Cell_0%2C+%5Cell_1%2C+%5Ccdots%2C+%5Cell_%7Bs-1%7D%5C%7D.&bg=ffffff&fg=000000&s=0&c=20201002)
 be an
be an 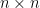 complex Hermitian matrix which means
complex Hermitian matrix which means 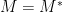 where
where  denotes the conjugate transpose operation. Let
denotes the conjugate transpose operation. Let 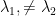 be two different eigenvalues of
be two different eigenvalues of 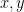 be the two eigenvectors of
be the two eigenvectors of  and
and 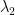 , respectively.
, respectively.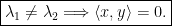
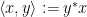 denotes the usual inner product of two vectors
denotes the usual inner product of two vectors 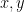 .
.
 of the complete graph
of the complete graph 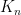 are
are  where the eigenvalue
where the eigenvalue  has (algebraic) multiplicity
has (algebraic) multiplicity  and the eigenvalue
and the eigenvalue  has multiplicity
has multiplicity  .
.
 with
with  , is the following:
, is the following: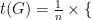 the product of all non-zero eigenvalues of
the product of all non-zero eigenvalues of 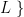 .
.