In this post, I will discuss my own understanding of the spectral sparsification paper by Daniel Spielman and Nikhil Srivastava (STOC 2008). I will assume the following:
- The reader is a beginner, like me, and have already glanced through the Spielman-Srivastava paper (from now on, the SS paper).
- The reader has, like me, a basic understanding of spectral sparsification and associated concepts of matrix analysis. I will assume that she has read and understood the Section 2 (Preliminaries) of the SS paper.
- The reader holds a copy of the SS paper while reading my post.
First, I will mention the main theorems (actually, I will mention only what they “roughly” say).
The Main Theorems
SS Theorem 1. It is possible to construct a spectral sparsifier 





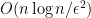
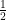

where
, an
vector, is a real valued function defined over the vertices of
and $\tilde{L}$) are the Laplacian matrix of
The above theorem says, the Laplacian quadratic form of 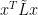
SS Theorem 2. It is possible to approximately compute the effective resistances 

Is an approximation of
SS Corollary 6. Approximate effective resistances
The Dots, Waiting to be Connected
The main questions are:
- How do we prove the existence of such a probability distribution which lets us generate a spectral sparsifier?
- How do we efficiently compute/approximate these probabilities?
The answer to these questions can be found through weaving elegant connections among some apparently disconnected/loosely-connected dots. I will mention these dots as D1,D2,… and walk the reader through the connections.
D1. Effective resistance 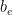
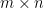


where 


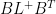
D2. (depends on D1) We can construct the
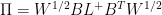
It was proved in [SS Lemma 3] that
is a projection matrix, and hence
.
- Rank of
.
- All eigenvalues of
.
- Diagonal elements of

D3. (depends on D2) The diagonal entries of
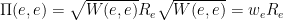
Thus we are interested in computing (either exactly or approximately) the diagonal entries of
D4. Now consider an 


where
- Edge
is the number of samples taken to generate the sparsifier
is the weight of the edge
D5. (depends on D4) It can be noted that the number of times an edge was actually sampled within ![\mathbb{E}[\tilde{w}_e]= w_e](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Ctilde%7Bw%7D_e%5D%3D+w_e&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[S]= I](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BS%5D%3D+I&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{E}[\tilde{L}]=L](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Ctilde%7BL%7D%5D%3DL&bg=ffffff&fg=000000&s=0&c=20201002)
D6. (depends on D4) Since
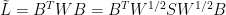
Note that we want to make 
D7. ([SS Lemma 5] Rudelson-Vershynin Lemma) Roughly, this lemma says the following. Suppose we draw 

D8. (depends on D7, D2, D3) Suppose the probability with with each edge

Then, using the Rudelson-Vershynin lemma (D7), it can be proved that


(This is proved in the SS paper after stating the Rudelson-Vershynin lemma.) Observe that

and hence 
D9. [SS Lemma 4] (depends on D8) This lemma says that, given D8, that is, if
then
Essentially, this proves [SS Theorem 1].
D10. (depends on D9) If the probability distribution used to sparsify is approximated, and the estimate is (roughly speaking) bounded by certain factor 


This proves [SS Corollary 6].
Now that we have proved [SS Theorem 1], we are left to prove [SS Theorem 2].
D11. (depends on D1) Let 



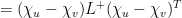
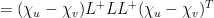

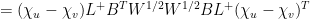

Suppose 
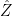
Actually, we will compute 

D12. This a special version (due to Achlioptas) of the famous Johnson-Lindenstrauss theorem. Roughly speaking, this tells that members of any fixed set of 


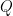
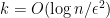

D13. This is the Spielman-Teng linear system solver (STsolver), which can be used to generate approximate solutions to system of linear equations involving Laplacians. This algorithm runs in expected time 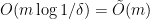
is the number of non-zero entries in
is a predetermined approximation error which is introduced to the generated solution
D14. (uses D12) We use D12 to project the

where 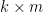
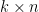
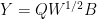


D15. (depends on D14, uses D13) Note that 


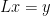









where we absorb the 
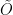
D16. (depends on D11, D15) Now we pick an appropriate value of
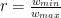
which makes the final running time of approximating the effective resistances to
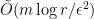
Therefore, we have proved [SS Theorem 1].
We Are Done
To summarize,
- First we showed that we can obtain a spectral sparsifer if we sample from a certain probability distribution (see D4).
- Then we showed that these probabilities are proportional to the diagonal entries of the projection matrix
- We also showed that the diagonal entries of the projection matrix
- Next we showed that our reweighting scheme does not distort the quadratic form of
- We also showed that approximating the effective resistances (as opposed to exactly computing them) does not hurt the sparsifier too much [SS Corollary 6] (see D10).
- So now we ask:
- (a) How do we approximate the effective resistances?
- (b) How fast?
- We show that the effective resistance of any given edge is equal to the norm of the difference of two columns of a certain matrix
- We used a special version of the Johnson-Lindenstrauss lemma (due to Achlioptas) to project the columns of this matrix into lower dimensions. This projection is guaranteed to preserve pairwise distances (that is, norms of the differences between the columns). This lower-dimensional projection is the matrix
- Then we approximated this matrix using Spielman-Teng linear system solver for Laplacian systems (see D15).
- Lastly we show that if we set the value the approximation parameter
That’s all for today, folks. Please let me know if you spot any gap/mistake in the explanations.

Very well-written indeed! We need more from you.
Thanks a lot. I have been reading the Kelner-Levin paper and Koutis-Miller-Peng paper that built on top these ideas. Insha-Allah I will write about them later.